OPPO数据中的台湾基石基于Flink SQL构建实时数据仓库
OPPO数据中的台湾基础:基于Flink SQL构建实时数据仓库
一、OPPO实时数仓的演进思路
1、OPPO业务与数据规模
每个人都知道OPPO是一款智能手机,但他们不知道OPPO与互联网和大数据之间是什么关系。下图概述了OPPO的业务和数据:
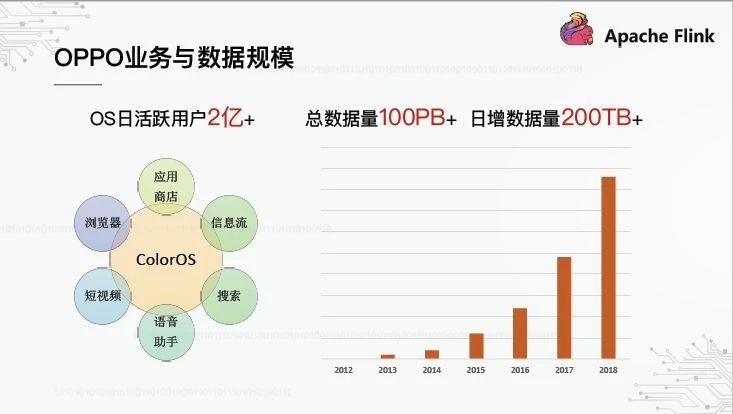
作为一家手机制造商,OPPO已经定制了基于安卓的ColorOS系统,目前拥有超过2亿活跃用户。围绕ColorOS,OPPO建立了许多互联网应用程序,如应用程序商店、浏览器、信息流等。在运行这些互联网应用程序的过程中,OPPO积累了大量的数据。上图右侧是总体数据规模的演变:从2012年起,增长率将为每年2-3倍。到目前为止,总数据量已超过100PB,每日数据量已超过200TB。
为了支持如此大量的数据,OPPO开发了一套完整的数据系统和服务,并逐渐形成了自己的数据中心系统。
2、OPPO数据中台
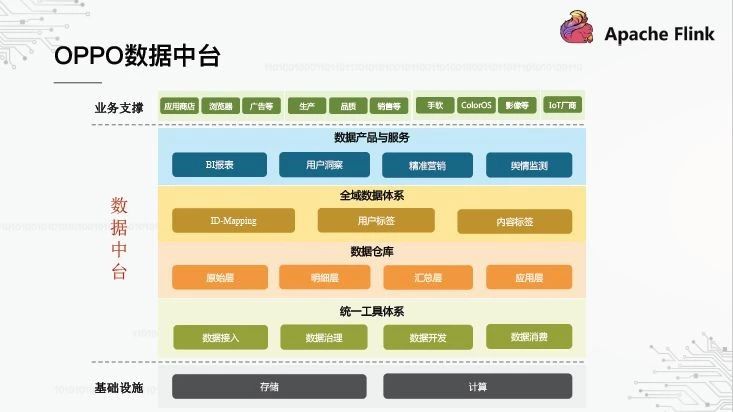
今年,每个人都在谈论台湾的数据。OPPO如何理解台湾的数据?我们将其分为四个层次:
最底层是统一工具系统,它涵盖了“访问-治理-开发-消费”的完整数据链。
基于该工具系统,构建了数据仓库,并将其划分为“原始层-细节层-概要层-应用层”,这也是一种经典的数据仓库体系结构。
再往上是全球数据系统。什么是全球数据系统?是通过公司的所有业务数据形成统一的数据资产,如身份映射、用户标签等。
最终,数据需要业务使用场景驱动的数据产品和服务。
以上是OPPO数据中心的整个系统,数据仓库处于一个非常基础和核心的位置。
3、构建OPPO离线数仓
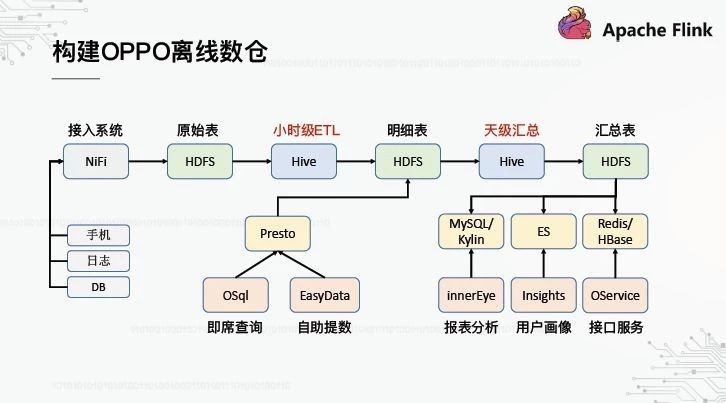
在过去的两三年里,我们的重点一直放在离线数据仓库的建设上。上图大致描述了整个施工过程。首先,数据源基本上是移动电话、日志文件和数据库。我们已经建立了一个基于Apache NiFi的高可用性和高吞吐量的访问系统,它将统一地把数据放到HDFS以形成原始层。接下来,基于Hive的小时级ETL和日级汇总Hive任务分别负责计算和生成详细层和汇总层;最后,应用层基于OPPO内部开发的数据产品,主要是报表分析、用户描述和界面服务。此外,中间细节层还支持基于Presto的即席查询和自助查询。
随着离线数据仓库的逐步完善,对实时数据仓库的需求越来越强烈。
4、数仓实时化的诉求

对于实时数据仓库的需求,每个人通常都是从业务的角度来看待它,但事实上,从平台的角度来看,实时也能带来实际的好处。首先,从业务角度来看,将会有报告、标签、界面等实时应用场景。请分别参考上图左侧的案例。其次,在平台端,我们可以从三种情况看到:第一,OPPO的大量批处理任务从0点开始,通过T 1进行处理,这将导致计算负载的集中爆发和集群的巨大压力;其次,标签导入也是一个T 1批处理任务,每次完全导入都需要很长时间。第三,数据质量的监控也必须是T 1,导致一些问题不能及时发现。
由于业务端和平台端都有这种实时需求,OPPO如何建立自己的实时头寸?
5、离线到实时的平滑迁移
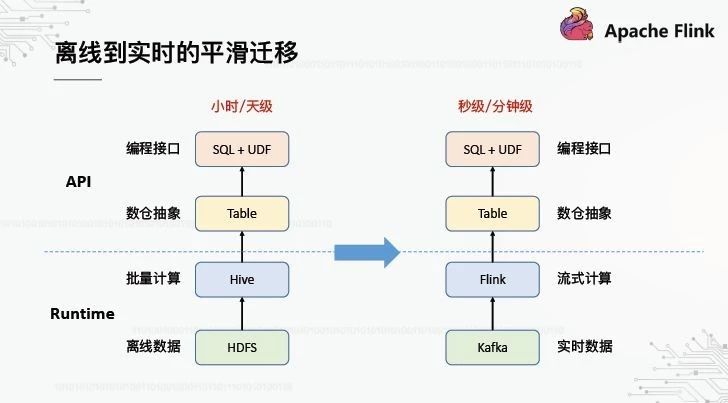
无论是一个平台还是一个系统,它都离不开上层和下层:上层是API,它是面向用户的编程抽象和接口;下层是运行时,它是面向内核的执行引擎。我们希望从离线到实时的迁移是平稳的,这意味着什么?从API的角度来看,数据仓库的抽象是表,编程接口是SQL UDF。在离线数据仓库时代,用户已经习惯了这种应用编程接口,在迁移到实时数据仓库之后,最好保持一致。从运行时层面来看,计算引擎从Hive发展到Flink,存储引擎从HDFS发展到卡夫卡。
基于以上想法,只有前面提到的离线仓库管道需要修改,以获得实时仓库管道。
6、构建OPPO实时数仓
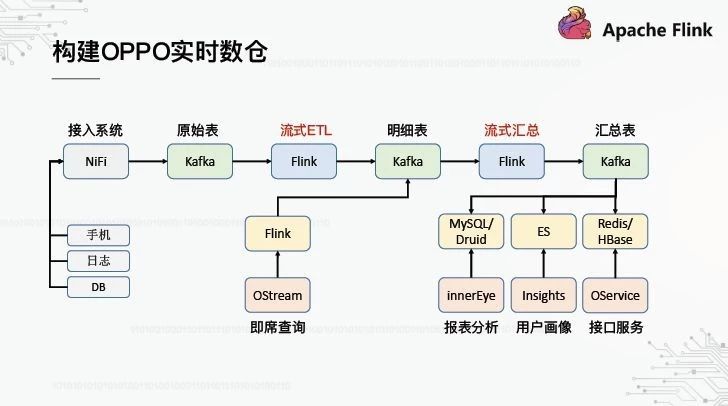
从上图可以看出,整个管道基本上类似于离线数据仓库,除了Hive被Flink取代,HDFS被Kafka取代。从整体流程来看,基本模型是相同的,还是由原始层、细节层、汇总层和应用层的级联计算组成。
因此,这里的核心问题是如何建立基于Flink的管道。下面描述了我们基于弗林克SQL的一些工作。
二、基于Flink SQL的扩展工作
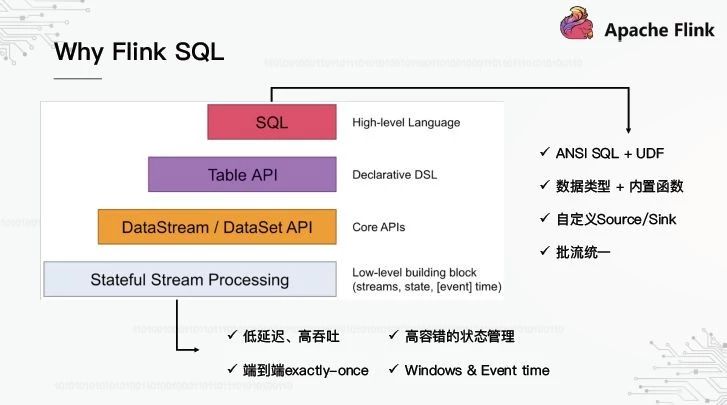
1、Why Flink SQL
首先,为什么要使用弗林克SQL?下图显示了Flink框架的基本结构。底部是运行时。我们认为这个执行引擎的核心优势有四个:第一,低延迟和高吞吐量;第二,端到端精确一次;第三,容错状态管理;第四,窗口事件时间的支持。基于运行时,抽象出三个层次的应用编程接口,而SQL处于顶层。
flinksqlpi的优势是什么?我们还从四个方面来看:第一,支持美国标准协会的SQL标准;其次,它支持丰富的数据类型和内置函数,包括常见的算术运算和统计聚合。第三,可以定制源/汇,基于此可以灵活地扩展上游和下游。第四,批处理流是统一的,相同的SQL可以离线或实时运行。
那么,如何基于flinksqlpi编程呢?以下是一个简单的演示:
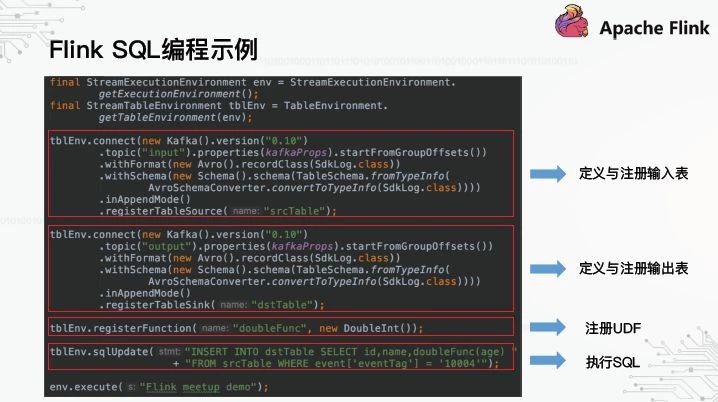
首先,定义并注册输入/输出表。这里创建了两个Kaffa表来指定卡夫卡的版本和主题;它对应于。下一步是注册UDF,因为没有UDF的定义。最后是执行真正的SQL。可以看出,为了执行SQL,需要做很多编码工作,这不是我们想要向用户展示的界面。
2、基于WEB的开发IDE
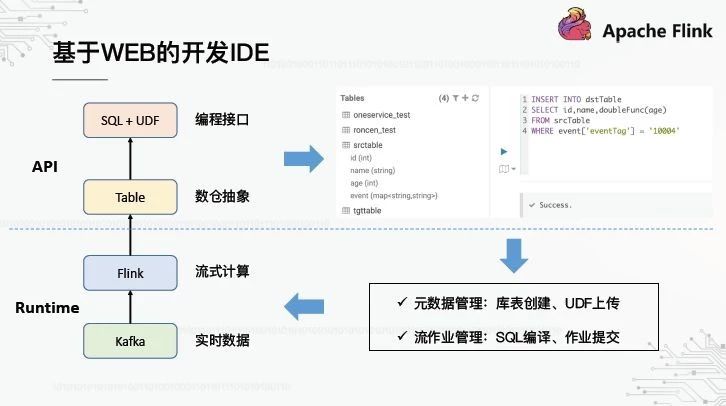
如前所述,数据仓库的抽象是表,编程接口是SQL UDF。对于用户来说,平台提供的编程接口应该类似于上面显示的,那些使用HUE进行交互式查询的人应该熟悉它。左边的菜单是表列表,右边是SQL编辑器。您可以直接在它上面编写SQL并提交它来执行。为了实现这种交互模式,默认情况下不能实现Flink SQL。中间有缺口。总而言之,有两点:第一,元数据管理,如何创建一个库表,以及如何上传UDF,以便以后可以直接在SQL中引用;第二,管理SQL作业,如何编译SQL,如何提交作业。
在技术研究的过程中,我们在2017年发现了优步的开源AthenaX框架。
3、AthenaX:基于REST的SQL管理器
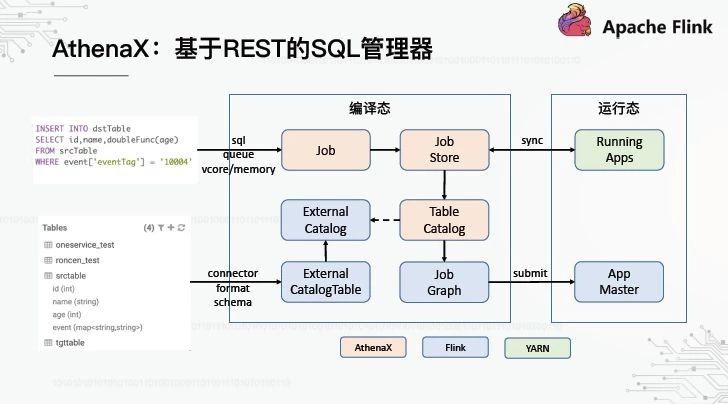
雅典aX可以被看作是一个基于REST的SQL管理器。它如何管理SQL作业和元数据?
对于SQL作业提交,AthenaX有一个作业抽象,它封装了要执行的SQL和作业资源等信息。所有作业都由作业商店托管,该商店定期与运行中的应用程序进行匹配。如果没有,相应的工作将提交给纱。
对于元数据管理来说,核心问题是如何将外部创建的库表注入到Flink中,以便能够在SQL中识别它们。事实上,Flink本身保留了与外部元数据接口的能力,分别提供了两个抽象:ExternalCatalog和外部目录。AthenaX在此基础上封装了一个TableCatalog,并在接口级别进行了一些扩展。在提交SQL作业的阶段,AthenaX将自动向Flink注册表目录,然后调用Flink的SQL接口将SQL编译成Flink的可执行单元作业图,最后提交给纱线生成新的应用。
AthenaX已经定义了TableCatalog接口,但是它没有提供直接可用的实现。那么,我们如何实现它来接收我们已经拥有的元数据系统呢?
4、Flink SQL注册库表的过程
首先,我们需要了解Flink SQL如何在内部注册库表。整个过程包括三个基本的抽象:表描述符、表工厂和表环境。
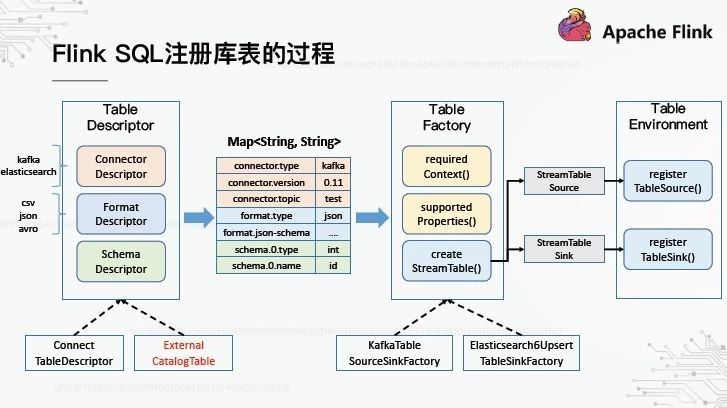
TableDescriptor,顾名思义,是对表的描述。它由三个子描述符组成:第一个是连接器,它描述数据的来源,如卡夫卡,专家系统等。第二种是格式,描述数据的格式,如csv、json、avro等。第三个是模式,它描述了每个字段的名称和类型。TableDescriptor有两个基本实现——ConnectTableDescriptor用于描述内部表,即以编程方式创建的表。ExternalCatalogTable用于描述外部表。
使用表描述符,接下来需要表工厂根据描述信息实例化表。不同的描述性信息需要不同的表工厂来处理。Flink如何找到匹配的TableFactory实现?事实上,为了确保框架的可伸缩性,Flink使用了Java SPI机制来加载所有声明的表工厂,并通过遍历搜索哪个表工厂与表描述符匹配。在传递给TableFactory之前,TableDescriptor被转换为映射,所有描述信息都以键值的形式表示。TableFactory定义了两种用于筛选匹配的方法——。一个是requiredContext(),用于检测某些键的值是否匹配,例如connector.type是否为kakfa;另一个是supportedProperties(),用于检测是否可以识别密钥。如果存在无法识别的密钥,则意味着没有匹配项。
在匹配正确的表工厂之后,下一步是创建一个真正的表,并在TableEnvironment中注册它。只有成功注册了该表,才能在SQL中引用它。
5、Flink SQL对接外部数据源
理清Flink数据库注册表的流程,给我们带来一个思考:如果外部元数据创建的表也可以转换成TableFactory可识别的映射,那么它就可以无缝地注册到TableEnvironment。基于这一思想,我们实现了弗林克SQL与现有元数据中心的对接。一般过程如下图所示:
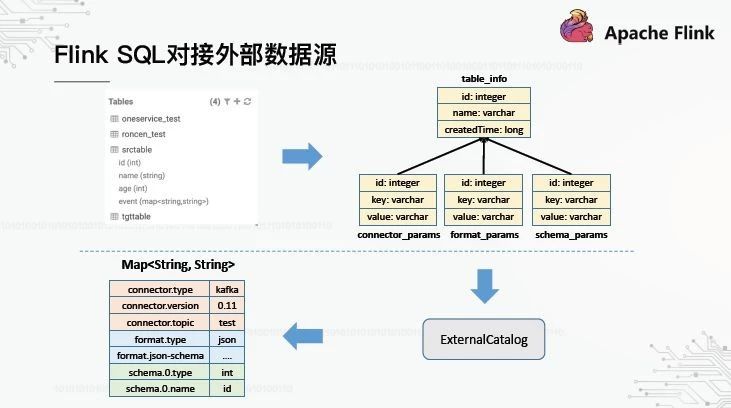
元数据中心创建的表在MySQL中存储元数据信息。我们使用一个表记录表的基本信息,然后另外三个表记录连接器、格式和模式分别转换成键值后的描述信息。它被分成三个表的原因是为了能够独立地更新这三个描述性信息。下面是定制的ExternalCatalog,它可以读取MySQL的四个表,并将它们转换成映射结构。
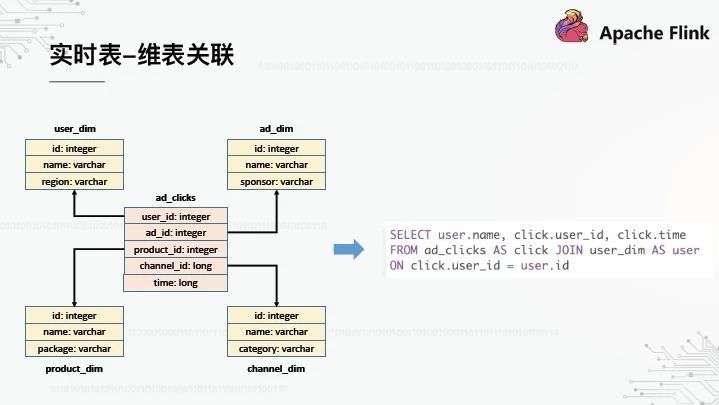
6、实时表 - 维表关联
到目前为止,我们的平台具有元数据管理和SQL作业管理的能力,但是仍然缺少一个真正对用户开放的基本特性。当我们建造几个仓库时,星型模型是不可避免的。这里有一个相对简单的例子:中间的事实表记录了广告的点击流,关于用户、广告、产品和渠道的维度表就在附近。
假设我们有一个SQL分析,我们需要将点击流表与用户维度表相关联。目前这应该如何在Flink SQL中实现?我们有两个实现,一个基于UDF,另一个基于SQL转换。让我们分开来谈。
7、基于UDF的维表关联
首先,基于UDF的实现要求用户用UDF调用将原始的SQL重写为SQL。这是userDimFunc,它的代码实现如上图右侧所示。UserDimFunc继承了Flink SQL抽象表函数,它是UDF类型之一,可以将任何一行数据转换为一行或多行数据。为了实现维度表的关联,在UDF初始化时,维度表的数据需要从MySQL中完全加载并缓存在内存缓存中。对于每一行数据的后续处理,TableFunction根据eval()中的user_id调用eval()方法来查找缓存,从而实现关联。当然,这里假设维度表数据相对较小。如果数据量太大,不适合完全加载和缓存,则此处不会扩展。
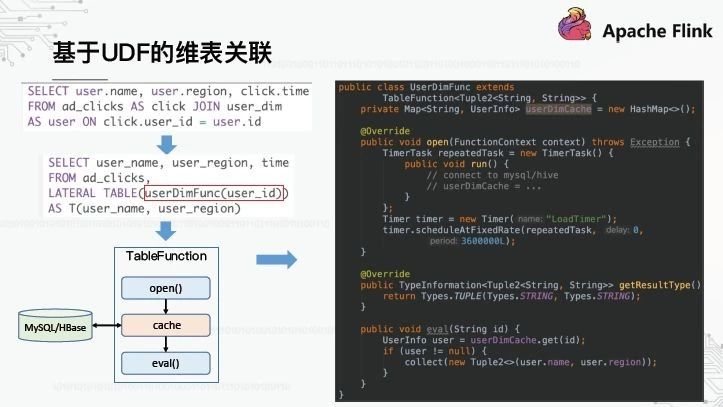
基于UDF的实现对用户和平台不是很友好:用户需要编写奇怪的SQL语句,比如图中的LateralTable该平台需要为每个相关场景定制一个特定的UDF,并且维护成本太高。有更好的方法吗?让我们看看基于SQL转换的实现。
8、基于SQL转换的维表关联
我们希望解决基于UDF的实施带来的问题。用户不需要重写原始的SQL,平台也不需要开发许多UDFs。一种想法是,在将SQL提交给Flink进行编译之前,可以添加一层SQL解析和重写来自动实现维度表的关联吗?经过一些技术研究和概念验证,我们发现它是可行的,所以称之为基于SQL转换的实现。这个想法将在下面解释。

首先,增加的SQL解析是为了识别SQL中是否有预定义的维度表,如上图中的user_dim。一旦维度表被识别,将触发SQL重写过程,并且由红色框标记的连接语句将被重写到新的表中。如何获得这张表格?我们知道“流表二元性”的概念是近年来在流计算领域发展起来的,而Flink也是这个概念的实践者。这意味着流和表可以在Flink中相互转换。我们将对应于广告点击的表格转换成一个流,然后调用平面图形成另一个流,最后转换回表格以获得广告点击用户。最后一个问题是,平面图如何实现维度表关联?
Flink中Stream的Flatmap操作实际上是执行一个RichFlatmapFunciton,调用它的flatmap()方法来转换每一行数据。然后,我们可以定制一个RichFlatmapFunction来实现维度表数据的加载、缓存、搜索和关联,其功能类似于基于UDF的TableFunction。
由于RichFlatmapFunciton的实现逻辑类似于TableFunction,为什么这种实现比基于UDF的方法更通用?核心点是可以使用多一层的SQL分析来获取维度表的信息(如维度表名称、关联字段、选择字段等)。)然后将其封装到JoinContext中,以传递给RichFlatmapFunciton,从而使表达式功能通用。
三、建实时数仓的应用案例
下面是一些典型的应用案例,它们都是在我们的平台上用Flink SQL实现的。
1、实时 ETL 拆分
这是一个典型的实时ETL链接,它将对应于每个服务的小表从大表中分离出来:
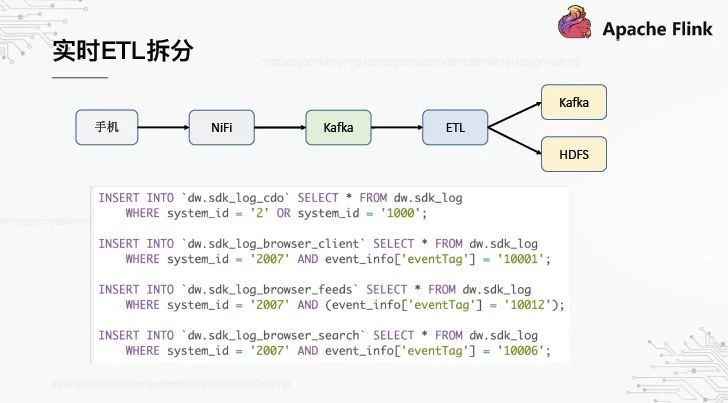
OPPO最大的数据源是手机端的隐藏点。手机应用程序的数据有一个特点,所有数据都通过几个统一的渠道报告。因为不可能每个企业都有新的嵌入点,所以我们必须升级客户并增加新的渠道。例如,我们有一个sdk_log通道,APP应用程序的所有嵌入式站点都向该通道报告数据,从而产生一个对应于该通道的巨大原始层表,每天有几十个TB。但事实上,每个企业只关心自己的那部分数据,这要求我们将ETL拆分到原始层。
这个SQL逻辑相对简单,只不过是根据特定的业务字段进行过滤,并将它们插入到不同的业务表中。它的特点是多行SQL最终合并成一个SQL并提交给Flink执行。每个人都担心的是,如果它包含4个SQL,它会读取相同的数据4次吗?事实上,在Flink的SQL编译阶段会进行一些优化,因为最后一点是同一个卡夫卡主题,所以数据只会被读取一次。
此外,相同的Flink SQL用于离线和实时数据仓库的ETL拆分,分别属于HDFS和卡夫卡。Flink本身支持写HDFS的Sink,比如RollingFileSink。
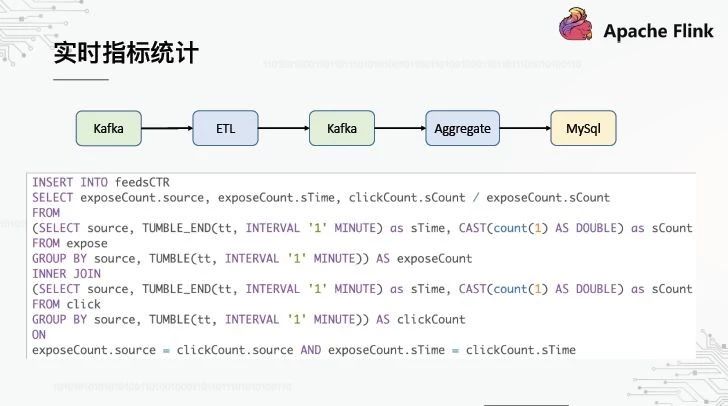
2、实时指标统计
这里是一个典型的计算信息流中心率的例子。分别计算一定时间内的曝光度和点击率,将点击率划分并导入到Mysql中,然后通过我们的内部报表系统进行可视化。这个SQL的特点是它使用了翻转窗口和子查询。
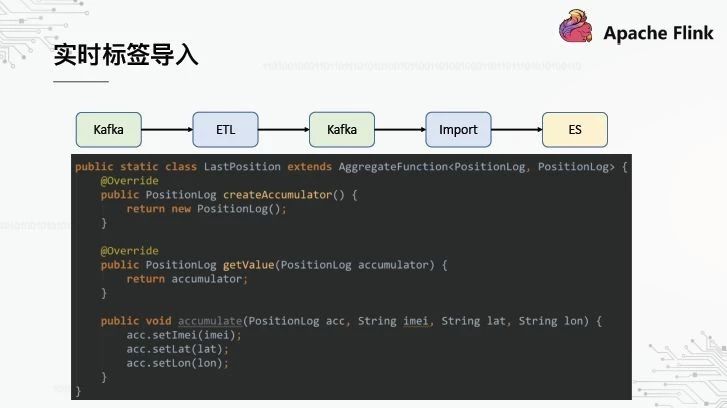
3、实时标签导入
这是一个实时标签导入的例子。移动终端实时感测当前用户的纬度和经度,将其转换成特定的兴趣点,导入专家系统,最后在标签系统上进行用户定位。

该SQL的特点是使用聚合函数。在5分钟的窗口中,我们只关心用户最新报告的纬度和经度。聚合函数是UDF类型,通常用于聚合指标的统计,如计算总和或平均值。在这个例子中,因为我们只关心最新的经度和纬度,所以我们每次都可以替换旧数据。
四、未来工作的思考和展望
最后,我想和你分享一些关于我们未来工作的想法和计划。我们还不太成熟。让我们和你讨论一下。
1、端到端的实时流处理
什么是端到端?一端是采集到的原始数据,另一端是通过报表/标签/界面对数据的展现和应用,中间的实时流连接着两端。目前,我们的实时流处理是基于SQL的,源表是卡夫卡,目标表是卡夫卡,通过卡夫卡后导入到Druid/ES/HBase。本设计的目的是提高整个流程的稳定性和可用性:首先,卡夫卡作为下游系统的缓冲,可以防止下游系统的异常影响实时流量的计算(一个系统保持稳定,同时其概率高于多个系统);其次,从卡夫卡到卡夫卡的实时流具有成熟的语义和有保证的一致性。
然后,上述端到端过程实际上由三个独立的步骤完成。每个步骤可能需要由不同角色的人来处理:数据处理需要数据开发人员,数据导入需要引擎开发人员,数据资本化需要产品开发人员。
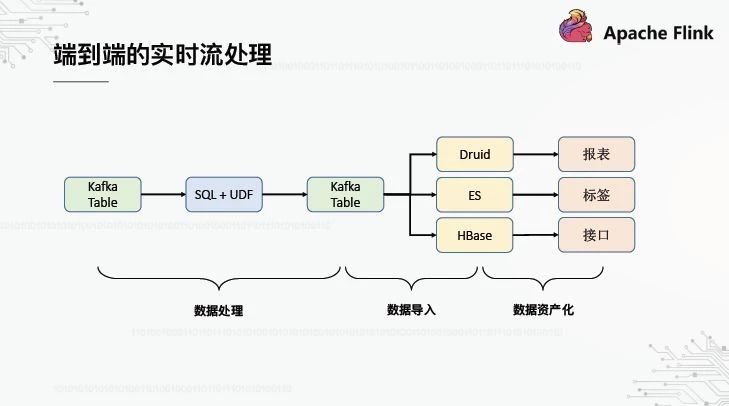
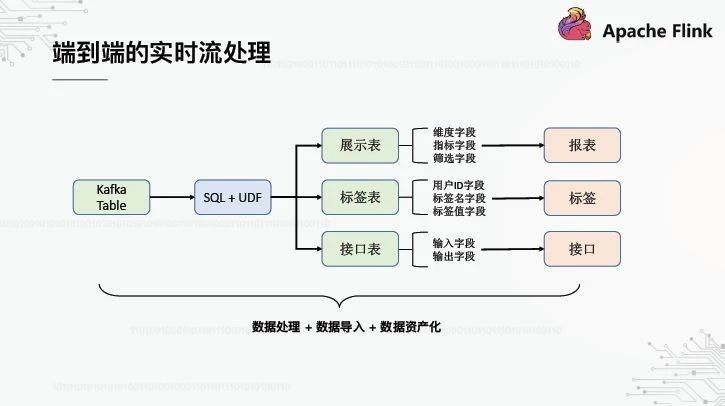
我们的平台能否实现端到端自动化,并且只需要提交一个SQL就能完成处理、导入和资本化这三个步骤?这样,我们在数据开发中看到的不再是卡夫卡表,而是面向场景的表示表/标签表/接口表。例如,对于显示表,在创建表时,平台会自动将实时流结果数据从Kafka导入Druid,然后在报表系统中自动导入Druid数据源,甚至自动生成报表模板。
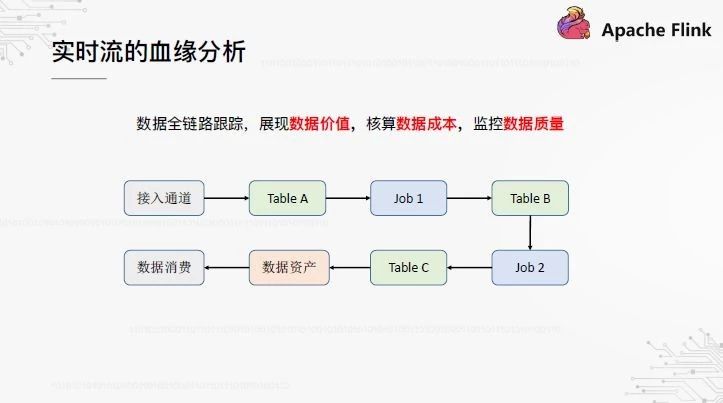
2、实时流的血缘分析
至于血缘关系分析,做过离线数据仓库的朋友都知道它的重要性,它在数据治理中起着不可或缺的关键作用。实时位置也是如此。我们希望建立一种端到端的血缘关系,从采集系统的访问通道到实时表,从中间到产品消费数据的实时操作,都可以清晰地显示出来。通过对血缘关系的分析,可以评估数据的应用价值,并计算数据的计算成本。
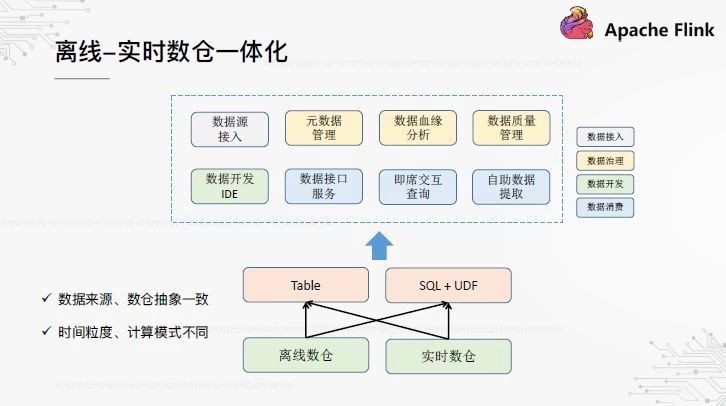
3、离线 - 实时数仓一体化
最后一个方向是离线实时数据仓库的集成。我们认为实时仓库不能在短期内取代离线仓库,两者共存是新常态。在离线盘点的时代,如何将积累工具系统应用于实时盘点,如何实现离线盘点和实时盘点的一体化管理?理论上,它们的数据源是相同的,上层抽象是表和SQL,但本质上它们也有不同的点,如时间粒度和计算模式。对于数据工具和产品,我们也在探索和思考实现完全集成需要哪些修改。
作者张军,OPPO大数据平台研发负责人
来源,人工智能前端(id:人工智能前端)
dbaplus社区欢迎所有技术人员提交他们的贡献。提交的电子邮件地址是editor@dbaplus.cn
活动推荐
2020年4月17日,北京,Gdevops全球敏捷运维峰会将开启年度首站!专注于数据库、智能运维、金融科技等领域,与阿里、中国银行、平安银行、中国邮政消费金融、中国联通大数据、新居网等技术代表合作。展望云时代数据库的发展趋势,解决运维转型的困境。
今晚8点和58家庭运营和维护专家杨经营将带来 《业务上云后,58到家运维平台的演进之路》 主题分享,回答如何对全业务托管公共云进行高效运营和维护。基于公共云的操作平台和IDC有什么不同?应该如何在公共云上构建操作和维护自动化?获取直播地址,添加vx:dbafeifei

