小米流媒体平台架构的演进与实践
原标题:小米流媒体平台架构的演进与实践
小米有很多业务线,涵盖从信息流、电子商务、广告到金融等多个领域。小米流媒体平台为小米集团提供各种业务的集成流媒体数据解决方案,主要包括数据采集、数据集成和流媒体计算三个模块。目前,日数据量达到1.2万亿,实时同步任务15,000项,实时计算数据1万亿。
随着小米业务的发展,流媒体平台经历了三次重大升级,以满足许多业务的各种需求。最新的迭代基于Apache Flink。流媒体平台的内部模块已经完全重建。与此同时,小米的业务正逐步从火花流转向弗林克。
背景介绍
小米流媒体平台的愿景是为小米所有业务线提供集成的基于平台的流媒体解决方案。具体来说,它包括以下三个方面:
流式数据存储:流式数据存储指的是消息队列。小米开发了一套自己的消息队列,类似于Apache kafka,但有自己的特点。小米流媒体平台提供消息队列的存储功能。流式数据接入和转储:将消息队列作为流数据的缓冲区后,有必要提供流数据访问和转储功能。流式数据处理:指平台基于Flink、Spark Streaming、Storm等计算引擎处理流数据的过程。
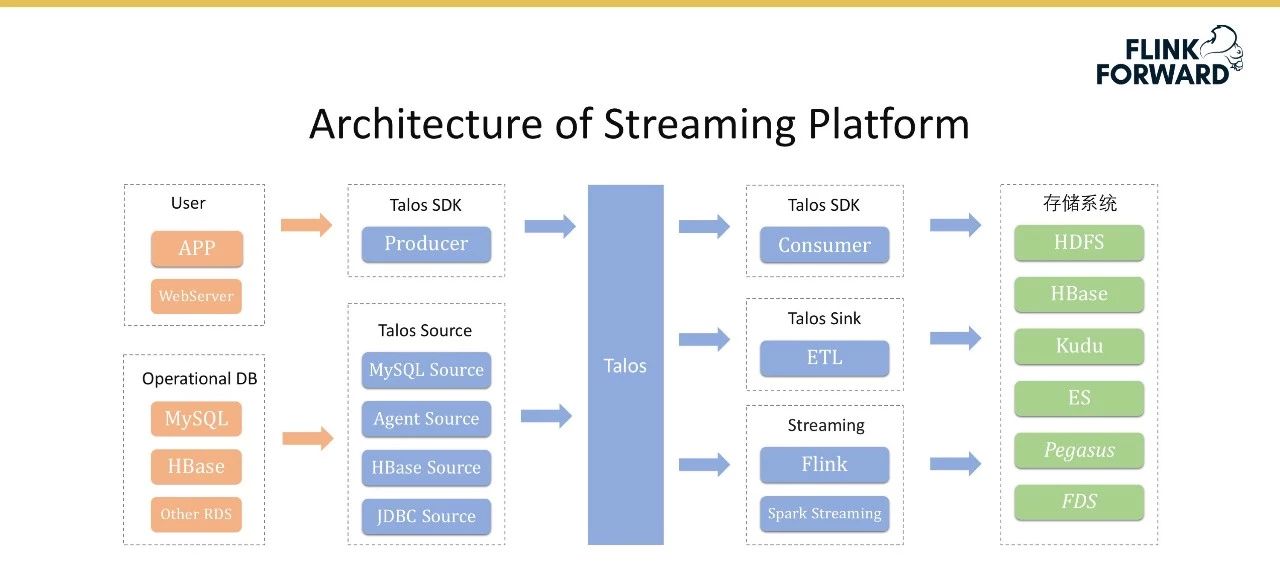
下图显示了流式平台的总体架构。第一列从左到右的橙色部分是数据源,包含两个部分,即用户和数据库。
用户是指用户的各种嵌入式数据,如用户应用程序和网络服务器的日志,其次是数据库数据,如MySQL、HBase和其他RDS数据。中间蓝色部分是流媒体平台的具体内容,其中Talos是小米实现的消息队列,其上层包含消费者SDK和生产者SDK。此外,小米还实现了一整套Talos Source,主要用于收集用户的数据和刚才提到的数据库。Talos接收器和源结合形成数据流服务,主要负责以极低的延迟将Talos数据转储到其他系统。信宿是一套标准化的服务,但还不够定制,Talos信宿模块将基于Flink SQL进行重构。
下图显示了小米的业务规模。在存储层面,小米每天大约有1.2万亿条信息,最高流量为每秒4300万条。仅Talos Sink每天就在转储模块中转储1.6 PB的数据,目前有近15,000次转储操作。每天有800多个流式计算作业和200多个Flink作业。Flink每天可以处理7000亿条消息,数据量超过1 PB。

小米流式平台发展历史
小米流平台的发展历史可以分为以下三个阶段:
Streaming Platform 1.0:小米流媒体平台1.0版建于2010年。它最初使用抄写员、卡夫卡和风暴,抄写员是一组解决数据收集和数据转储的服务。Streaming Platform 2.0:由于1.0版中的各种问题,我们开发了小米自己的消息队列Talos,包括Talos Source、Talos Sink,并连接到Spark Streaming。Streaming Platform 3.0:该版本在以前的版本中添加了模式支持,并引入了Flink和Stream SQL。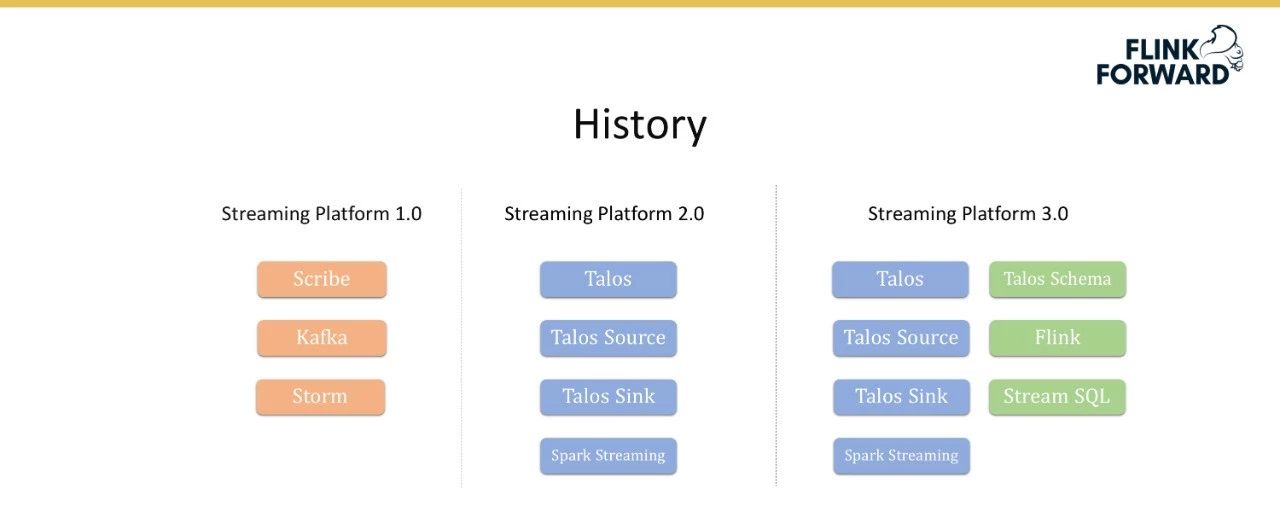
streaming platform 1.0作为一个整体是一个级联服务,包括前面的Scribe代理和Scribe服务器的多级级联,主要用于收集数据,然后满足离线计算和实时计算的场景。HDFS和希弗用于离线计算,卡夫卡和斯托用于实时计算。虽然这种离线加实时的方法基本上可以满足小米当时的业务需求,但仍然存在一系列问题。
首先,抄写员太多,并且缺少配置和包管理机制,导致维护成本非常高。抄写员采用的推送架构在异常情况下无法有效缓存数据,HDFS/卡夫卡数据相互影响。最后,当数据链路级联相对较长时,整个链路数据黑盒缺乏监控和数据检查机制。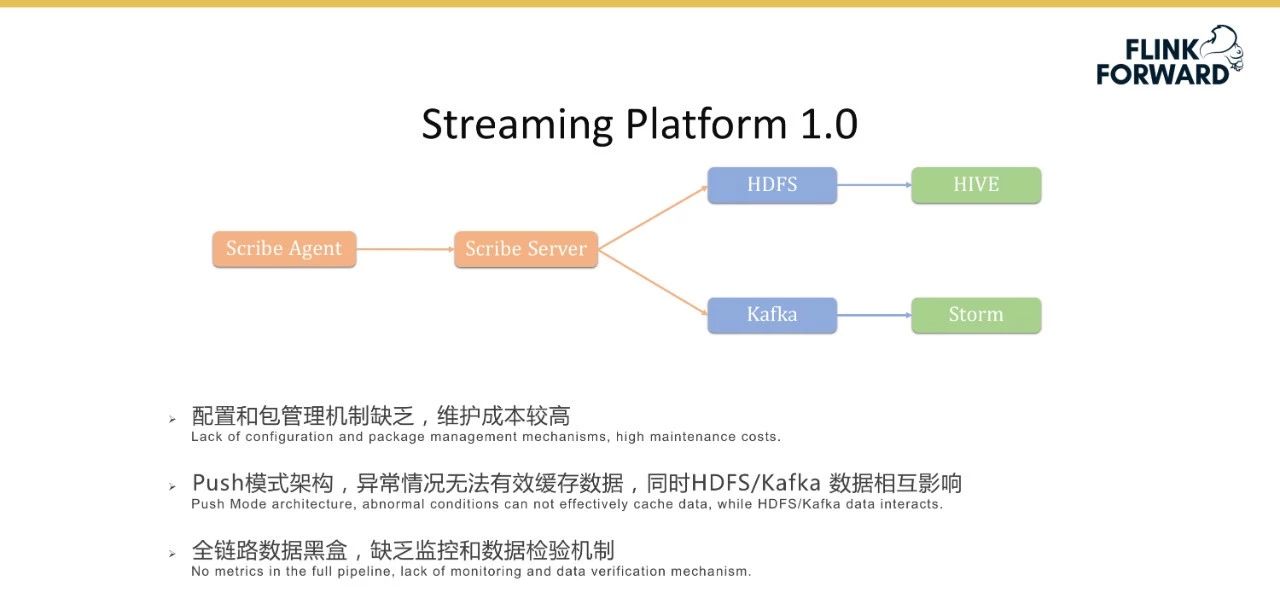
为了解决流媒体平台1.0的问题,小米推出了流媒体平台2.0。Talos被引入到这个版本中,以存储流数据作为数据缓冲区。左边是各种数据源,右边是各种接收器。原级联架构转换成星型架构,具有扩展方便的优点。
由于代理本身的数量和管理流程(具体数据都在一万级),本版本实现了一套配置管理和包管理系统,支持一次配置后代理的自动更新和重启。此外,小米还实施了分散配置服务。设置配置文件后,它们可以自动分发到分布式节点。最后,该版本还实现了数据的端到端监控,通过埋设点监控整个链路上的数据丢失和数据传输延迟。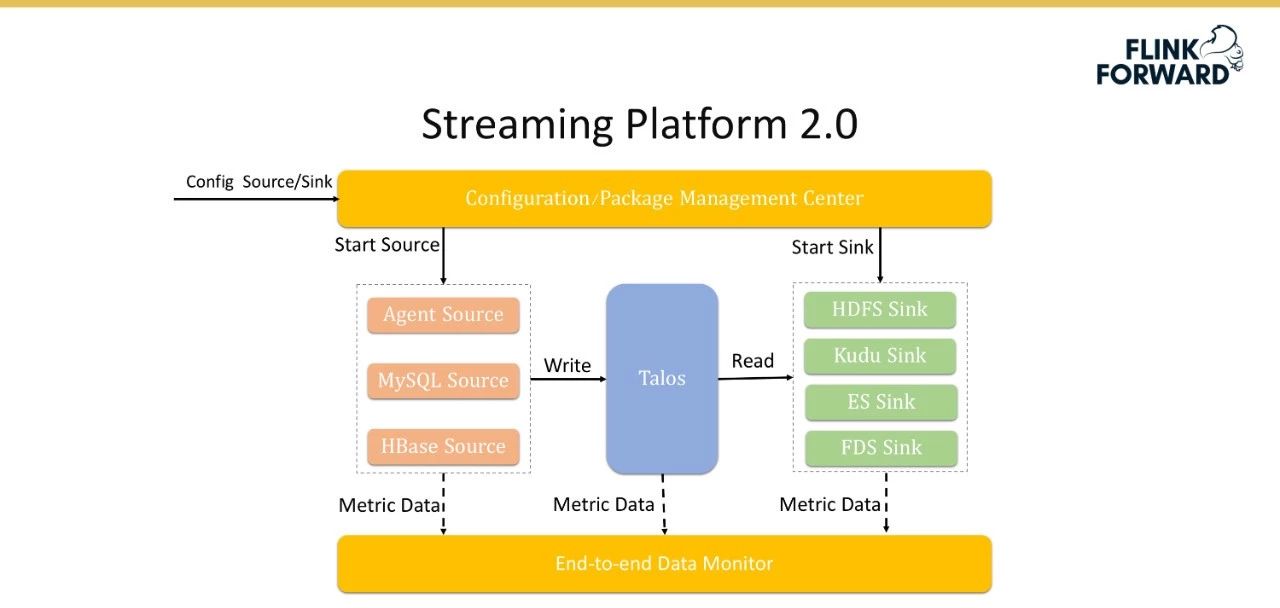
流媒体平台2.0的主要优势是:
引入了多源多接收器。以前,两个系统之间的数据需要直接连接。当前的体系结构将系统集成的复杂性从原来的0(M * N)降低到0(M * N);引入配置管理和包管理机制,彻底解决系统升级、修改、在线等一系列问题,减轻运行维护压力;引入端到端数据监控机制,实现全链路数据监控,量化全链路数据质量。基于产品的解决方案,避免重复建设,解决业务运营和维护问题。
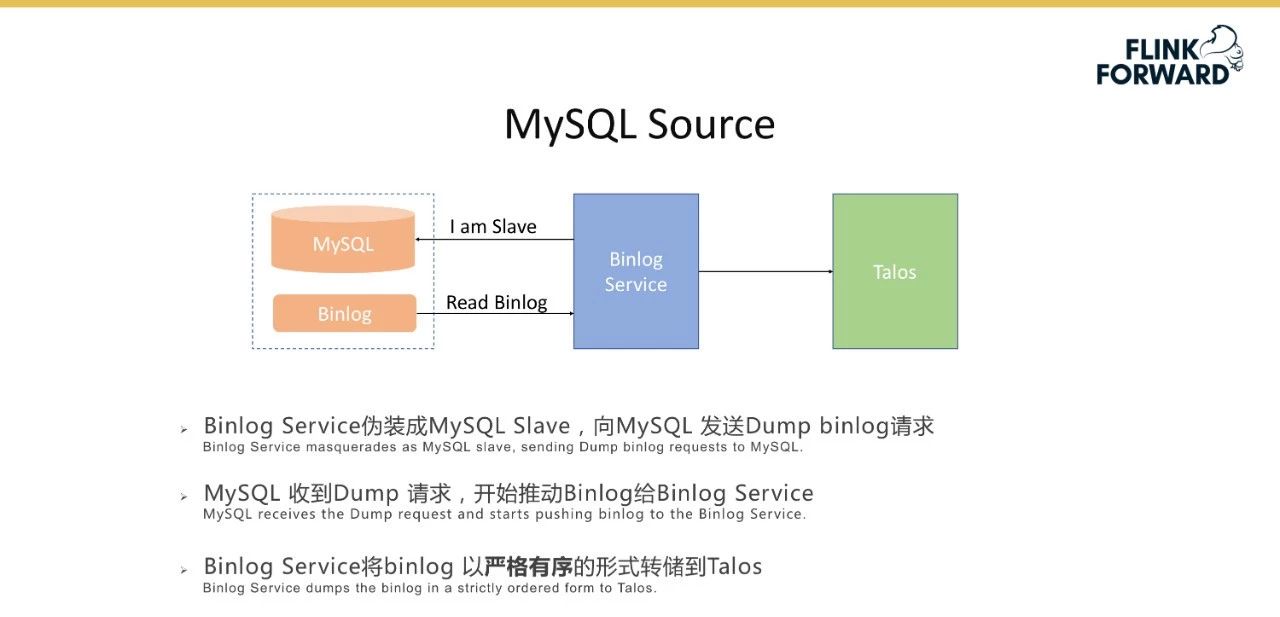
下图详细说明了MySQL同步的情况。场景是通过上述机制将MySQL表与消息队列Talos同步。具体过程是binlog服务将自己伪装成MySQL的从服务器,并向MySQL发送转储Binlog请求。MySQL在收到转储请求后,开始将Binlog提升为Binlog服务;binlog服务以严格有序的形式将Binlog转储到Talos。之后,将访问火花流作业,分析binlog,并将分析结果写入Kudu表。目前,该平台支持3000多个写入Kudu的表。下图显示了
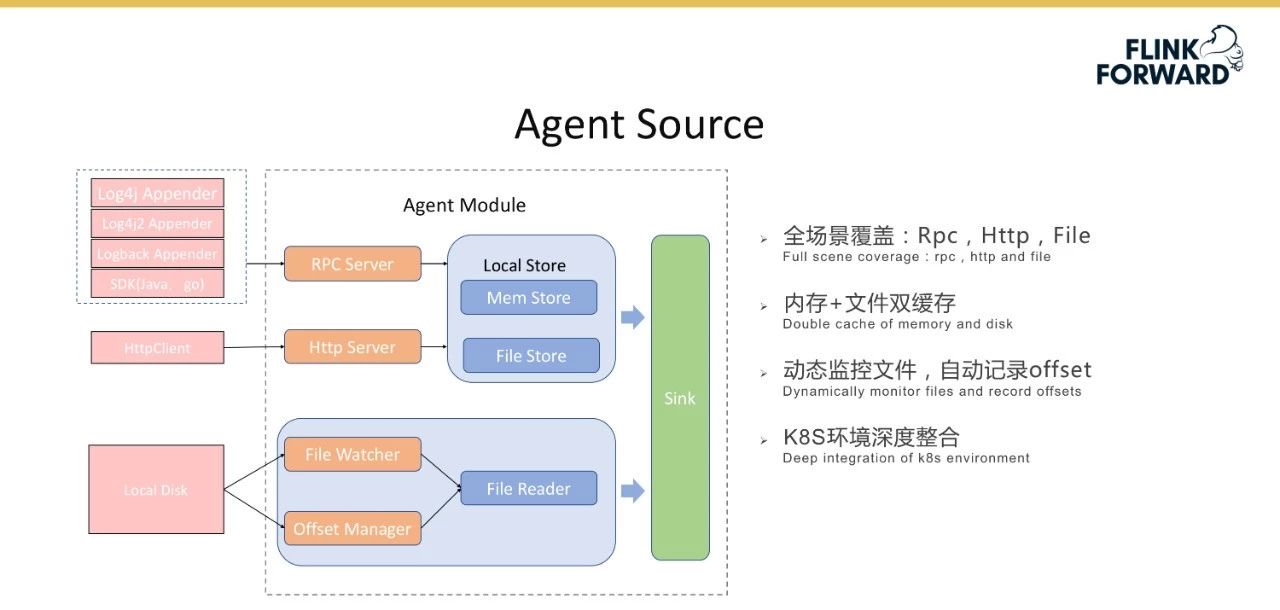
代理源的功能模块。它支持RPC和Http协议,可以通过文件监控本地文件,实现内存和文件的双重缓存,保证数据的高可靠性。该平台实现了记录器附加器和RPC软件开发工具包;基于RPC协议。HttpClient是为Http协议实现的;对于文件,实现文件观察器来自动发现和扫描本地文件,偏移管理器自动记录偏移。代理机制与K8S环境深度集成,可轻松与后端流计算相结合。
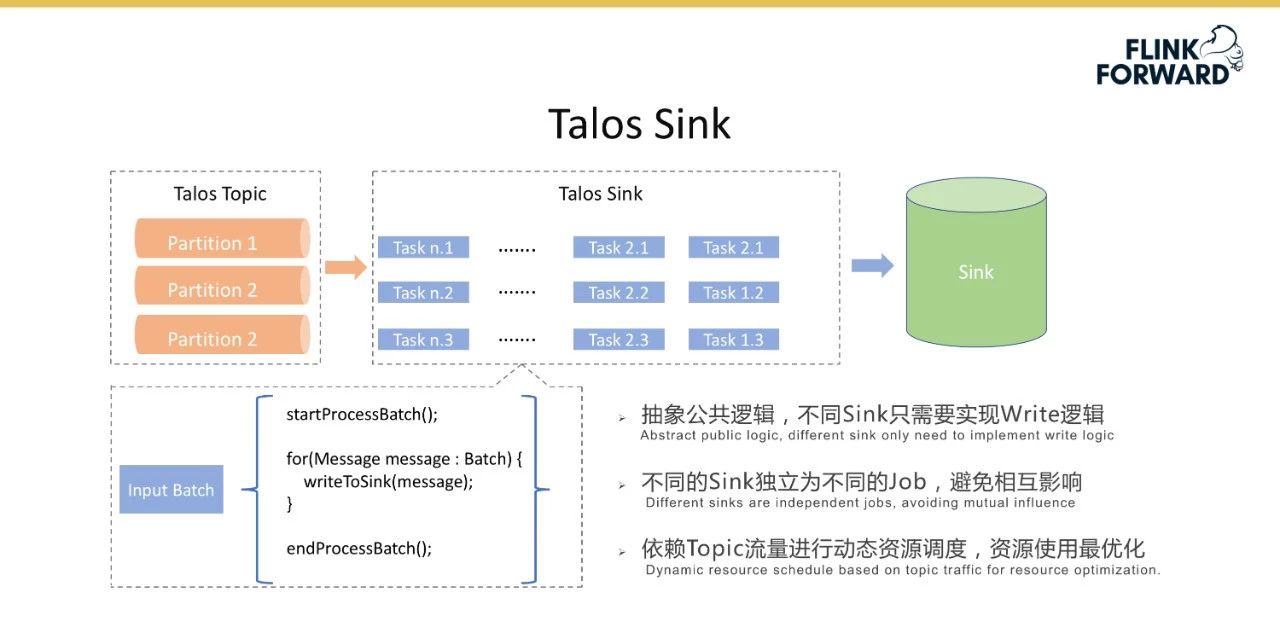
下图是Talos Sink的逻辑流程图,它实现了一系列基于火花流的过程。最左边是Talos主题的一系列分区片段,这些片段基于每个批处理抽象公共逻辑,例如startProcessBatch()和stopProcessBatch()。不同的接收器只需要实现写逻辑。不同的水槽相互独立,以避免相互影响。Sink在火花流(Spark Streaming)的基础上进行优化,根据主题流量实现动态资源调度,在保证系统延迟的前提下最大限度地节约资源。
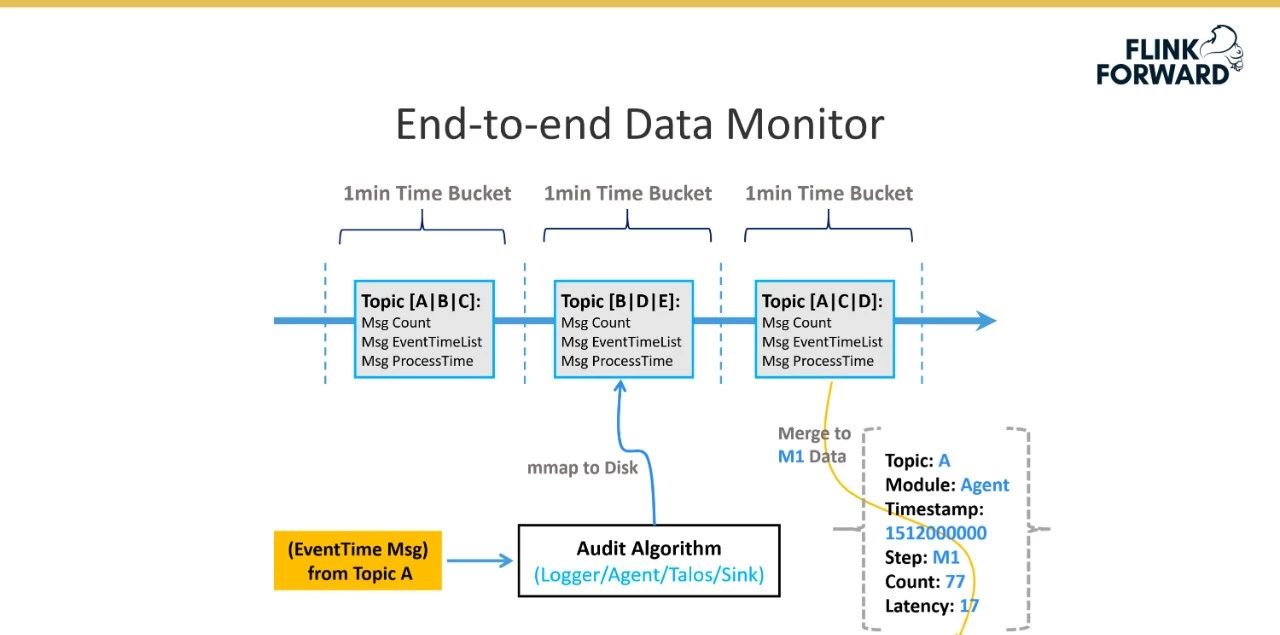
下图显示了平台实现的端到端数据监控机制。具体实现是每个消息都有一个时间戳EventTime,它指示消息实际生成的时间。时间窗口根据事件时间划分。窗户的尺寸是一分钟。数据传输的每一跳都会计算当前时间窗口内接收到的消息数,并最终计算消息的完整性。延迟是计算一跳的处理时间和事件时间之间的差值。
Streaming Platform 2.0目前有三个主要问题:

为了解决Streaming Platform 2.0的上述问题,小米进行了大量的研究,还与阿里的实时计算团队进行了一系列的沟通和交流。最后,决定使用Flink来改变平台的当前流程。以下是基于Flink的小米流媒体平台实践的具体介绍。
使用Flink改造平台的设计理念如下:
在Flink社区的帮助下,Flink在小米的登陆全面推进。一方面,流媒体的实时计算操作逐渐从火花和风暴(Spark and Storm)迁移到Flink,保证了原有的延迟和资源节约。目前,小米已经经营了200多家Flink业务。另一方面,预计Flink将用于转换Sink的流程并支持ETL,同时提高其运行效率。在此基础上,流式传输SQL会得到大力推广。将实现流产品,并引入流作业和流SQL的平台管理。基于Flink SQL转换Talos Sink支持业务逻辑
下图是流媒体平台3.0版的架构图,与2.0版的架构设计相似,只是表达角度不同。具体来说,它包括以下模块:
基于 Flink 的实时数仓
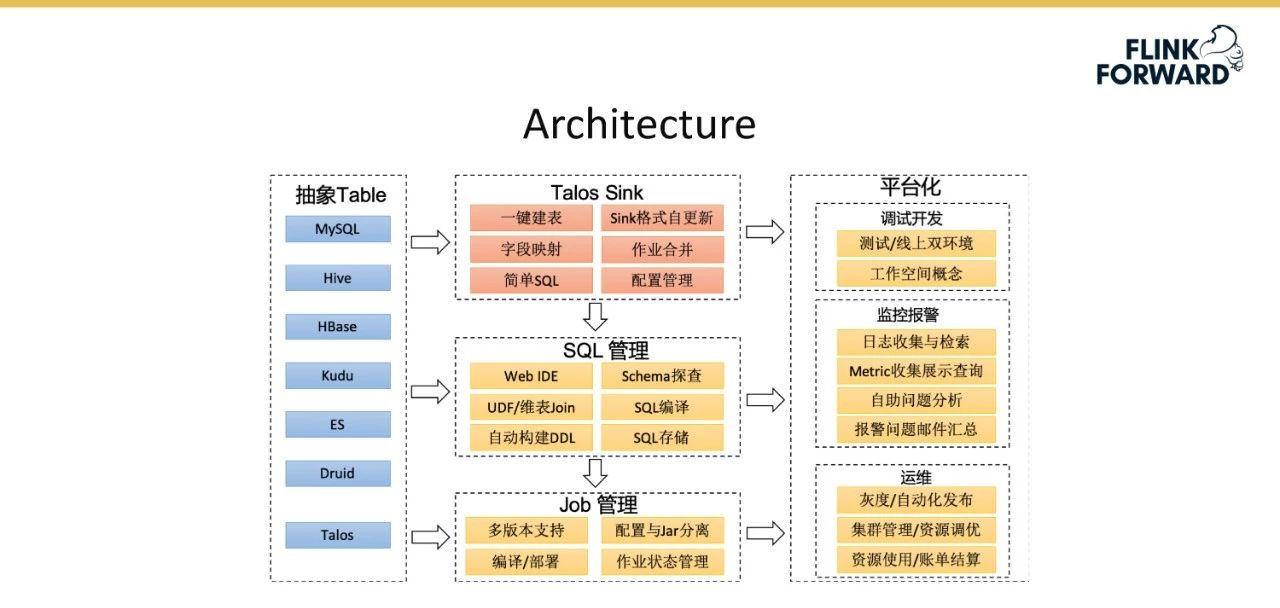
Job 管理
Job management提供作业生命周期管理、作业权限管理和作业标签管理等功能。支持作业操作历史显示,方便用户追溯;支持作业状态和延迟监控,失败的作业可以被自动拉起。

SQL 管理
主要包括以下四个步骤:
首先根据外部表获取表模式和表格式信息,用于解解释数据,如解序列化配置单元数据;然后后端生成默认连接器配置,主要分为三个部分,即不可修改、可由有默认值的用户修改、必须由没有默认值的用户配置。
将外部表转换为SQL DDL的过程如下图所示。
不可修改的配置假定使用了talos组件,那么连接器类型必须是Talos,并且不需要修改配置;默认值是从顶部开始消费,但用户可以从底部设置消费,这是一个具有默认值但用户可以修改的配置。但是,某些权限信息必须由用户配置。
进行三层配置管理的原因是为了尽可能降低用户配置的复杂性。表模式、表格式和连接1其他配置信息表单。在将SQL配置返回给用户后,用户可以填写可修改的配置,从而完成从外部表到SQL DDL的转换。红色字体表示用户修改的信息。
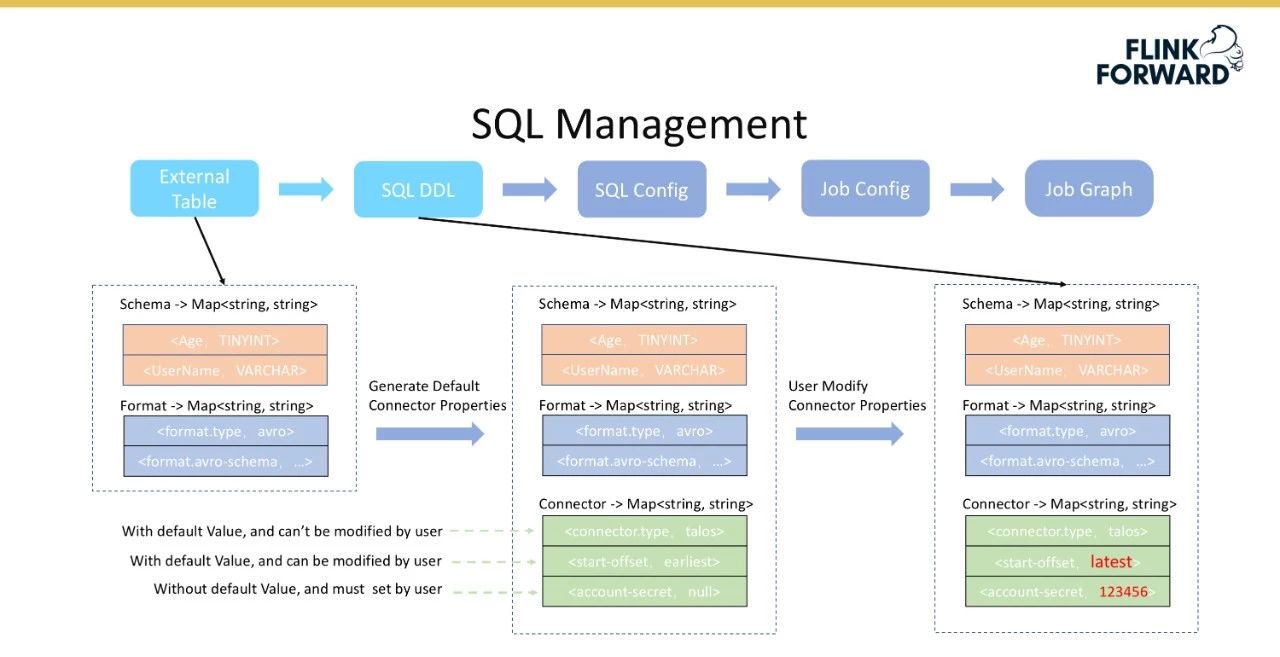
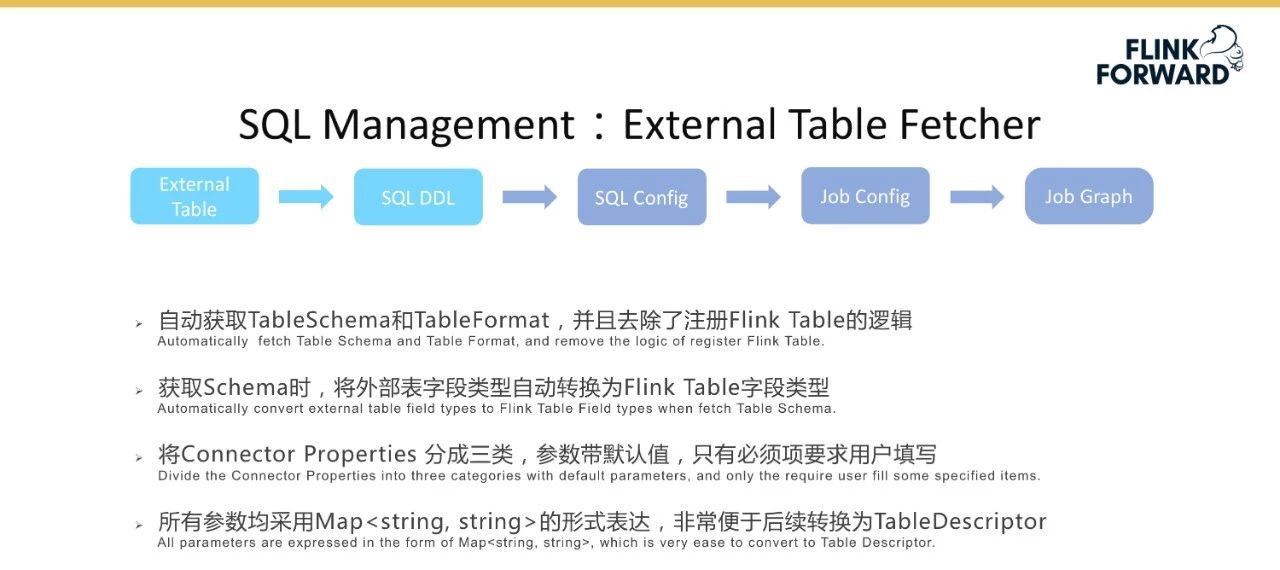
SQL管理引入了外部表功能。假设当用户选择在平台上消费一个主题时,这个特性将自动获得上面提到的表的模式和格式信息,并显示注册Flink表的逻辑被移除;获得模式后,该功能将自动将外部表字段类型转换为Flink表字段类型,并自动注册为Flink选项卡。同时,“连接器属性”分为三类,带有参数默认值,用户只需要填写必要的项目。所有参数都以映射(Map)的形式表示,这对于后续在Flink内部转换成TableDescriptor非常方便。
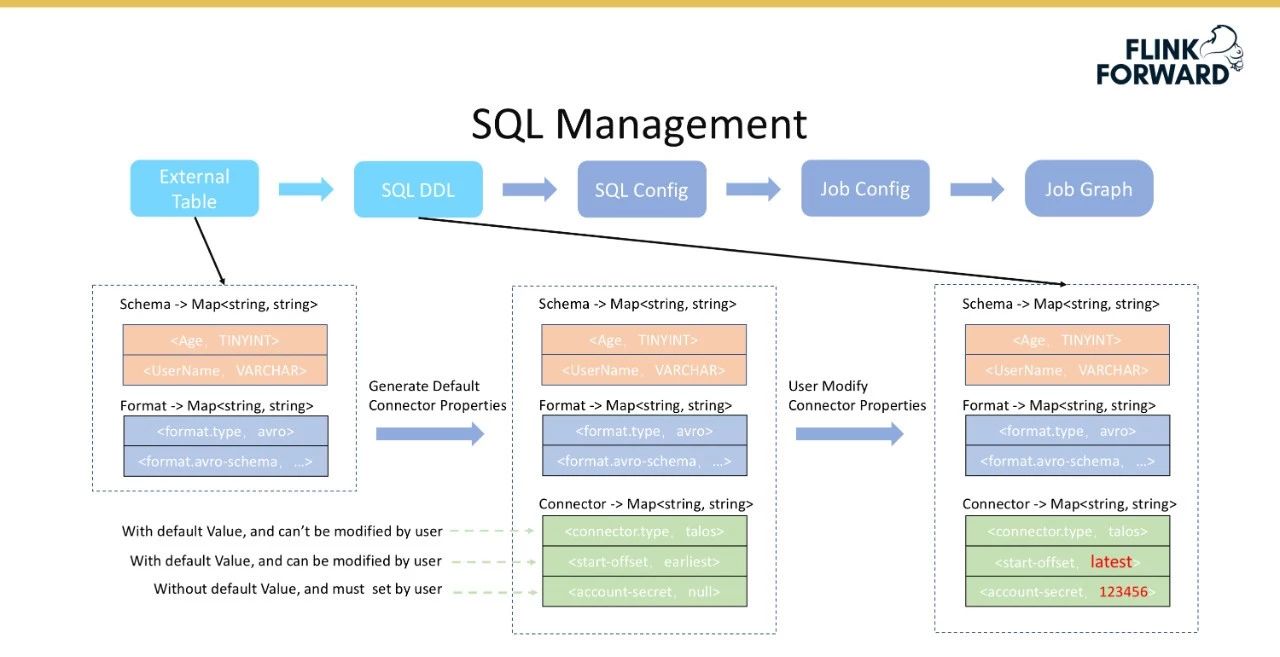
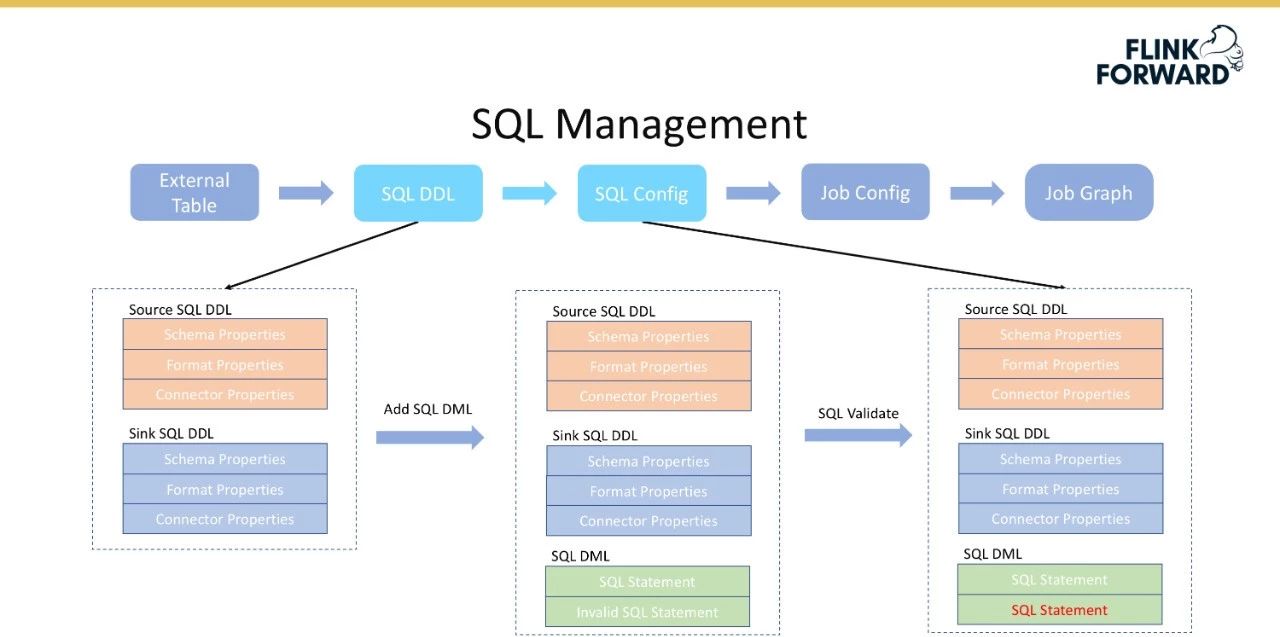
上面描述了SQL DDL的创建过程。基于已创建的SQL DDL,如源SQL DDL和宿SQL DDL,用户需要填写SQL查询并返回到后端,后端将验证该SQL,然后生成一个SQL配置,即一条SQL语句的完整表达式。下图显示了将
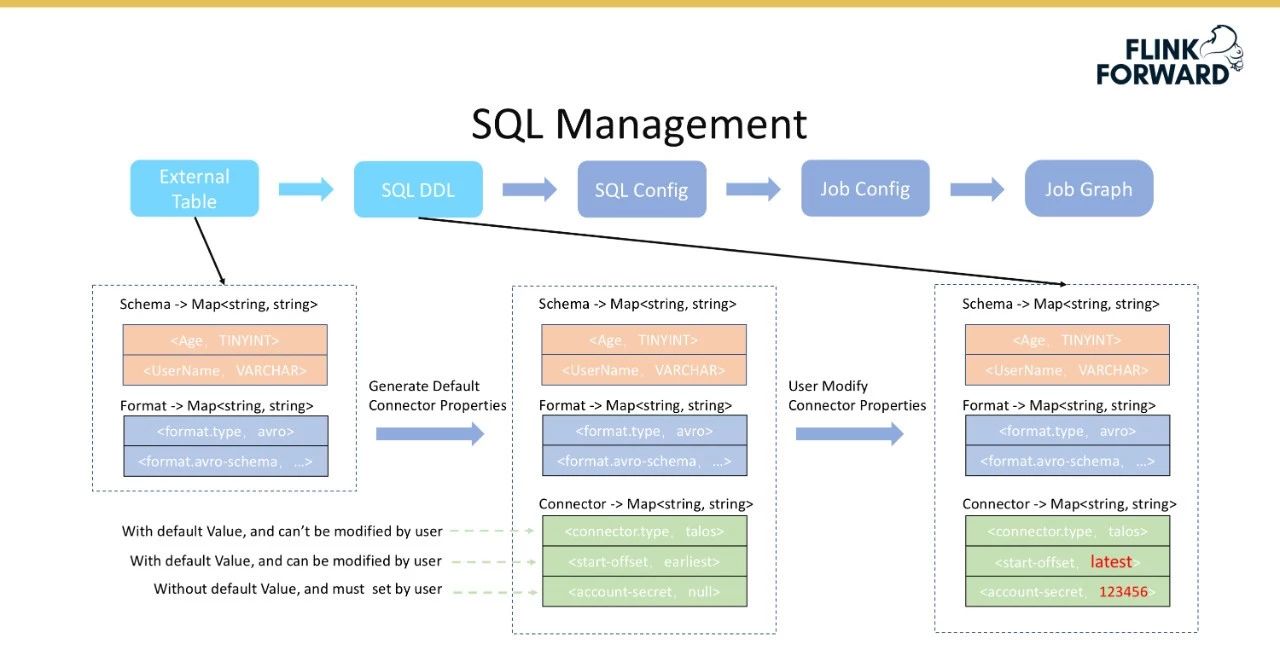
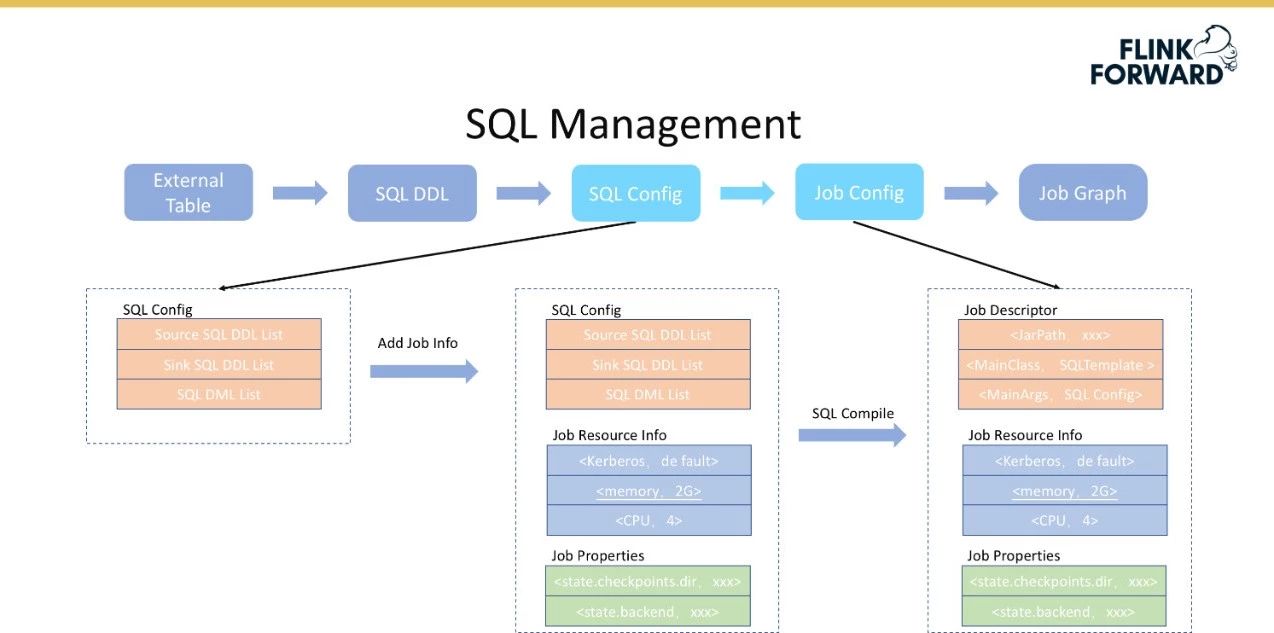
SQL配置转换为作业配置的过程。
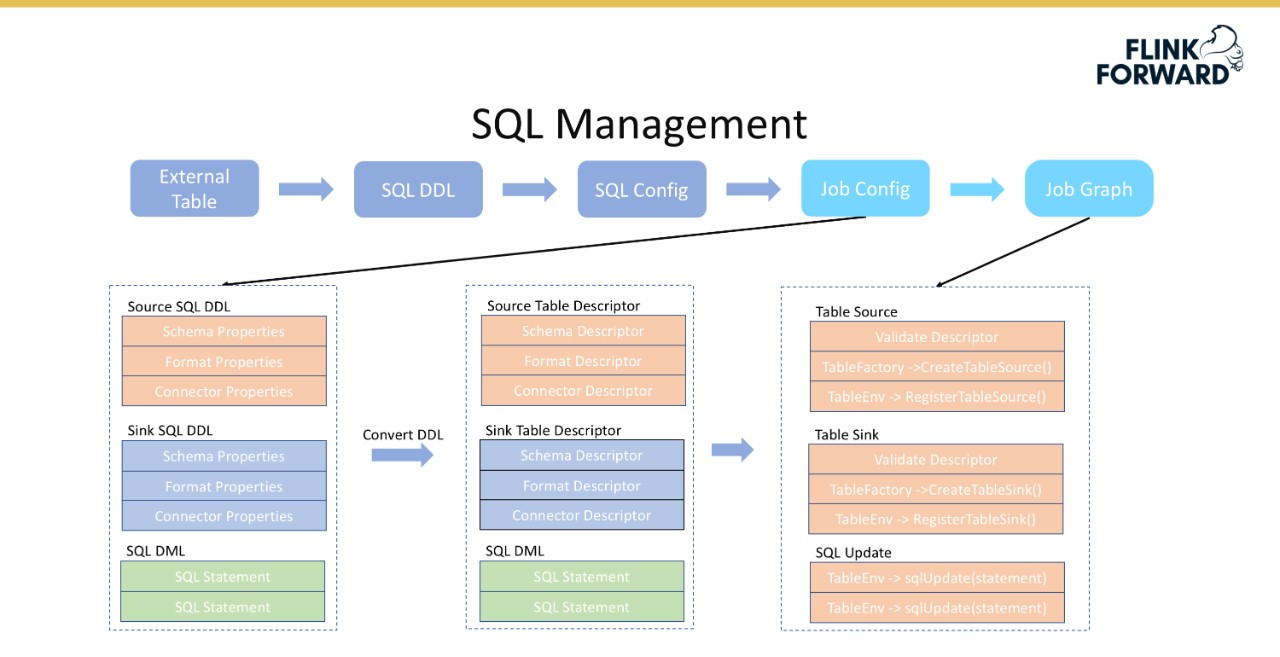
下图显示了将作业配置转换为作业图的过程。DDL中的模式、格式和属性与Flink中的表描述符一一对应。在这种情况下,可以通过调用Flink的相关内置接口,如CreateTableSource()、RegistorTableSource()等,轻松地将信息转换为表描述符。通过以上过程,DDL可以在Flink系统中注册直接使用。对于SQL语句,可以使用TableEnv的sqlUpdate()直接完成转换。将
SQL配置转换为模板作业的过程如下。前面填写的Jar包地址是模板的Jar地址,MainClass是模板作业。假设SQL DDL已经可用,它可以直接转换为表描述符,然后通过TableFactorUtil的findAndCreateTableSource()方法可以获得表源。表接收器的转换过程类似。完成前两个步骤后,最后执行sqlUpdate()操作。通过这种方式,可以将一个SQL作业转换成最后一个可以执行的作业图,并提交给集群运行。
Talos Sink采用了下图所示的三种模式:
小米流媒体平台的未来计划主要包括以下几点:
作者介绍:夏军,小米流媒体平台负责人,主要负责流媒体计算、消息队列、大数据集成等系统的研发,包括Flink、Spark Streaming、Storm、Kafka等开源系统以及小米自己开发的一系列相关系统。
-
这篇文章的作者:夏军
尚云查看云的栖息地号。点击此处查看更多信息:http://yqh.aliyun.com/? Utm _ content=g _ 1000100940
本文为阿里云内容,未经许可不得转载。
