打破数据壁垒构筑鲲鹏计算产业金字塔基础
原标题:突破数据壁垒,打造鲲鹏计算产业金字塔基础
“算力是新生产力,数据是新生产资料,而5G、AI和云是新生产工具。”华为Cloud AI产品与服务总裁侯金龙认为,在生产工具齐备的情况下,算力作为创造智能财富的能力,并没有对数据做到真正的开发。
随着5G、人工智能、云等技术的深入应用和集成,数据的急剧增加正在改变我们的生产和生活,但也带来了寻找、检索和使用数字困难等挑战。我们会发现没有这些数据的生产资料就不能产生价值。
以深圳为例,这座城市有200多万台摄像机,每天将产生80 PB的数据。如果您想将数据保存30天,您需要高达240 PB的数据存储空间,这很难实现,因此大量数据只能存储几天。根据预测,全球数据量将从2018年的33个ZB迅速增加到2025年的180个ZB。但是,保存的生成数据不到2%,应用的保存数据不到10%。
海量数据增长的背后是需要海量存储和计算的资源分配。如果计算能力不能提高,智能时代将永远不会面对无限增长和无用的数据。
No.1
自下而上 打破数据四重壁垒
数据对于互联网就像血液对于骨头一样重要。然而,今天,数据有四面无形的墙,“内部存储系统墙”、“数据库和存储链接墙”、“大数据和存储配置墙”和“数据库和大数据协调墙”。它们就像凝结在血管中的血凝块,阻碍大数据的自由流动。
麦肯锡曾经发现,在过去的十年里,数据流对全球国内生产总值的贡献增加了10.1%。从全球来看,连接性较高的经济体比连接性较低的经济体收入高40%。尽管纷繁复杂的数据孕育了各种机遇,但企业数据共享的概念仍远未达成共识,无法自由流动的数据已成为企业难以跨越的门槛。
在互联网时代很难解开数据的“死结”,而智能时代想要实现企业效率的提升和总拥有成本的降低,就必须要打破这四堵墙。
作为行业内具有前瞻性和创新性的企业,华为提出了一个全新的理念:从底层共同打造金字塔。
11月19日,华为在深圳宣布,将为鲲鹏的计算行业和开源数据虚拟化引擎HetuEngine推出全面的数据基础设施战略。这是华为在“鲲鹏升”双引擎全面推出计算策略后,从数据角度对计算策略的重申。
华为的数据基础架构战略专注于数据“挖掘-存储-计算-管理-使用”的整个生命周期,涵盖数据存储、数据处理、数据管理系统、数据虚拟化引擎等。从数据基础设施的底层开始,实现高效的数据共享和分析,降低成本,提高效率,最终突破数据围栏,使数据融合更加彻底。顶层是基于人工智能芯片、存储和华为云的三层架构。通过云对云的组合、云对云的培训和云对云的推理,该系统可以更快、更有效地使用。
可见,河图引擎可以屏蔽数据基础设施的复杂度,让开发者像使用数据库一样使用大数据,复用现有的生态、工具和技能。

“为了更好地发展数据产业,华为将推出开源河流地图引擎,其开源版本称为openHetu,将于2020年6月推出。我们将开放源代码内核,开发人员可以基于开放源代码定制它,包括数据源扩展、SQL执行策略等。实现快速应用对接,提高开发效率。”侯金龙介绍说河图引擎有四个核心能力,其中之一是统一安全。
在企业最关心的安全层面,通过细粒度动态授权、敏感数据自动感知等技术,实现异地异构数据源的集中安全配置和控制,使数据全局可控,数据授权时间一天比一天短,从而解决企业的数据安全和合规问题。
No.2
鲲鹏计算 全产业链开源的根基
通过其数据基础设施战略,华为与其合作伙伴建立了更紧密的联系,并向更多企业敞开了大门。事实上,全球科技企业正面临开源浪潮。当开源成为商业模式、企业生态和产业合作方式时,开源成为企业成长和生态繁荣的新渠道。
华为先后开放源代码项目,如ark编译器、服务器操作系统和GaussDB OLTP独立数据库。基于昆鹏的计算产业,华为正以开放的心态实施全产业链开源战略。
开源软件使用开源代码、免费分发和其他形式,减少了营销和
华为的整个产业链在开源方面更加彻底。它开启了从商品生产到流通和销售的整个过程。因为它参与生产过程,所以它将开放收入来源的风险降低到最低水平。这种前店后厂的合作模式也让顾客感到更加放心。
这种开源模式企业不仅需要胆识与气度,更需要深远的产业格局与核心技术实力支撑,因为这等于是将自己到手的利益与他人分享。侯金龙强调,华为不仅要向开发者开放硬件,更要发挥软硬协同的优势,释放更大的算力。
鲲鹏计算产业,由华为及其工业伙伴共同打造,包括个人电脑、服务器、存储、操作系统、中间件、虚拟化、数据库、云服务和工业应用。华为专注于开发华为鲲鹏和胜利处理器的双引擎基础芯片家族,为所有行业共同提供基于鲲鹏和胜利处理器的信息技术基础设施和工业应用。
“利用硬件能力,我们对外提供主板、SSD、网卡、RAID卡、Atlas模组和板卡,有限支撑合作伙伴发展服务器和PC等计算产品。软件方面开源操作系统、数据库和AI计算框架,使能伙伴发展自己品牌的产品。”侯金龙对鲲鹏计算产业的定位是“硬件开放、软件开源、使能合作伙伴”。
今年9月,华为在全连接大会上宣布了“一片云两翼双引擎”的鲲鹏计算产业布局。基于“鲲鹏崛起”双引擎,公司正式推出全面计算策略,宣布开源服务器操作系统GaussDB OLTP独立数据库,开启鲲鹏主板,拥抱多元化计算时代。为了支持鲲鹏工业生态的建设和发展,华为计划在未来五年投资15亿美元发展鲲鹏工业生态。
据估计,整个计算产业生态系统在世界上拥有近2万亿美元的市场空间,在中国拥有超过1.1万亿人民币的市场空间。从行业趋势和应用需求的角度来看,多元化计算时代正在到来。多种数据类型和场景推动了计算架构的优化。多种计算架构的组合是实现最佳性能计算的必然选择。
面向多样性计算时代,即便是巨头企业也无法将触手蔓延向整个产业链。华为率先通过鲲鹏产业,全产业链深度的开源与合作,与IT业伙伴共同做大产业蛋糕。
No.3
鲲鹏+昇腾 给算力插上翱翔的翅膀
国内外有不少企业从事开放生态。2014年,微软在其云平台Azure上支持并使用了Linux,并成为开源倡导者。百度在中国已经开设了71个项目,阿里巴巴73个项目,腾讯75个项目。
但是像鲲鹏的计算行业一样,很少有企业实现了整体开源。除了支持产业链的原因之外,计算能力跟不上开源数据的爆炸式增长,使得许多企业没有开源数据,但无法从数据管理转向数据操作。
随着5G、人工智能和云的普及,数据量正以惊人的速度增长。从1080P到4K和8K,视频数据量将增加40倍,从4K到4K虚拟现实将增加6倍以上。未来,每辆自动驾驶汽车每天将产生高达64 TB的数据。如果数据存储在硬盘上,这与新的动力电池组没有什么不同。
自动驾驶技术不仅需要云数据支持,还需要超强的计算能力来支持实时智能分析。在正式发布自动驾驶软件之前,所有汽车工厂都需要在数据中心进行大量的自动驾驶模型培训。在过去的五年里,通用处理器的发展遇到了一系列的技术瓶颈。它的单核性能平均每年增长不到10%。市场认为是发展指南的摩尔定律已经开始放缓。一些人甚至指出,它正在接近极限,计算架构需要新的创新。正是在这种背景下,华为的鲲鹏和曾生诞生了——,并以全新的计算架构面对未来。
过去华为的名字很少与计算这个词联系在一起。事实上,华为已经在计算领域积累了15年。
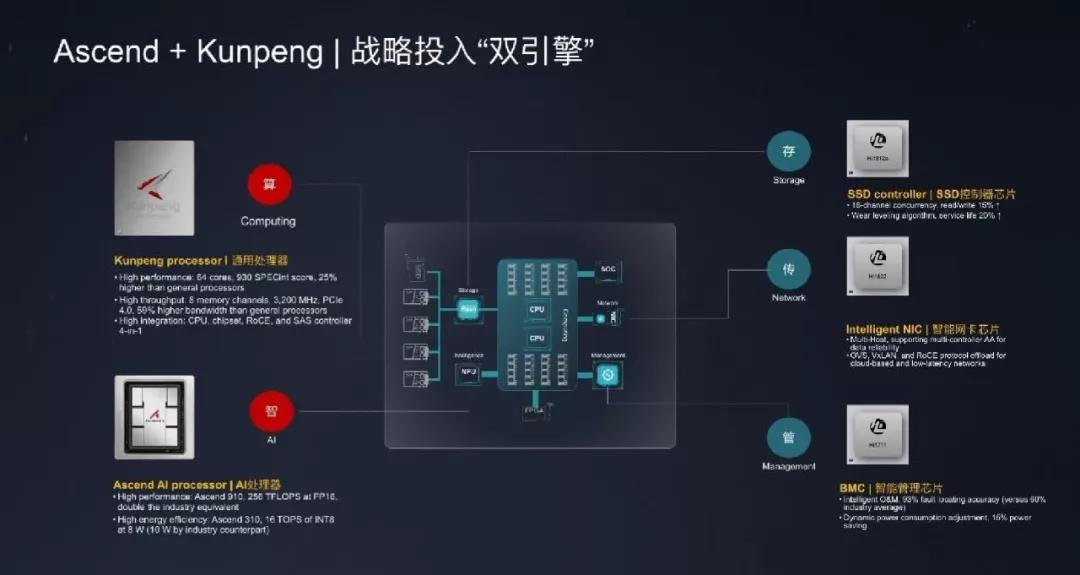
处理器是整个计算行业的基础,只有“核心”才是强大的。自2004年以来,已投资研发第一款嵌入式处理芯片,目前已投资2万多名工程师。这次和人力的最终结果是昆鹏处理器、泰山服务器解决方案和面向计算行业的升序系列处理器。
在华为鲲鹏和胜利的两个基本芯片家族中,鲲鹏代表通用计算,胜利代表人工智能加速能力。算力的水平决定了智能科技产业成熟商用的时间。
computing industry先后经历了大型计算机、小型计算机/x86服务器的阶段,创造了一个经验丰富、成本低廉的云计算时代。在当前“云人工智能5G”技术叠加的背景下,计算行业正进入一个多计算能力的阶段,企业也需要一个div